이전 글에서 Windows 환경에서 C++ 을 사용해서 LLaMA2 를 실행하는 방법을 공유했습니다.
2024.06.03 - [개발] - Meta의 LLM 모델 LLaMA 2를 Windows에서 실행하기
Meta의 LLM 모델 LLaMA 2를 Windows에서 실행하기
1. 개요Meta에서 공개한 LLaMA 2 모델은 파라미터 개수가 7B, 13B, 70B 인 3가지 사이즈로 제공이 됩니다. 여기서 B는 Billion(10억)의 약자입니다. 가장 작은 모델인 7B는 파라미터 개수가 70억개이고, INT8
lastlaugher.tistory.com
하지만 AI 연구개발하시는 분들은 대부분 python을 사용하기 때문에 python으로 LLaMA2를 사용하려는 수요가 더 많을 것 같습니다.
이전에 설명했던 llama.cpp의 python wrapper 프로젝트를 사용하겠습니다. github 페이지는 아래와 같습니다.
https://github.com/abetlen/llama-cpp-python
GitHub - abetlen/llama-cpp-python: Python bindings for llama.cpp
Python bindings for llama.cpp. Contribute to abetlen/llama-cpp-python development by creating an account on GitHub.
github.com
이 프로젝트에서 clone 받아도 되지만, pip로 설치하는 방법이 더 간단합니다.
아래처럼 설치가 가능합니다.
pip install llama-cpp-python
하지만!! 이렇게 설치하면 문제가 있는데요. CPU 모드로 설치가 되기 때문에 엄청 느립니다. 간단한 질문을 해도 1분 이상 걸립니다.
아래처럼 CUBLAS 옵션을 cmake 환경변수로 넣어주게 되면, GPU로 LLaMA2 모델을 실행할 수 있게 됩니다. (아래는 Windows 에서 환경변수 세팅하는 방법이고 다른 OS들은 각각 알맞은 방법으로 해야합니다)
set CMAKE_ARGS="-DLLAMA_CUDA=ON"
pip install llama-cpp-python --force-reinstall --upgrade --no-cache-dir
설치가 완료되면 아래 코드로 테스트가 가능합니다. 인자 값들은 본인 환경에 맞게 적당히 수정해 주셔야 합니다.
from llama_cpp import Llama
llm = Llama(model_path="llama-2-7b-chat.Q5_K_M.gguf", n_gpu_layers=36, n_ctx=4096, n_batch=128, verbose=True)
output = llm("Q: Name the planets in the solar system? A: ", max_tokens=64, stop=['Q:', '\n'], echo=True)
print(output['choices'][0]['text'])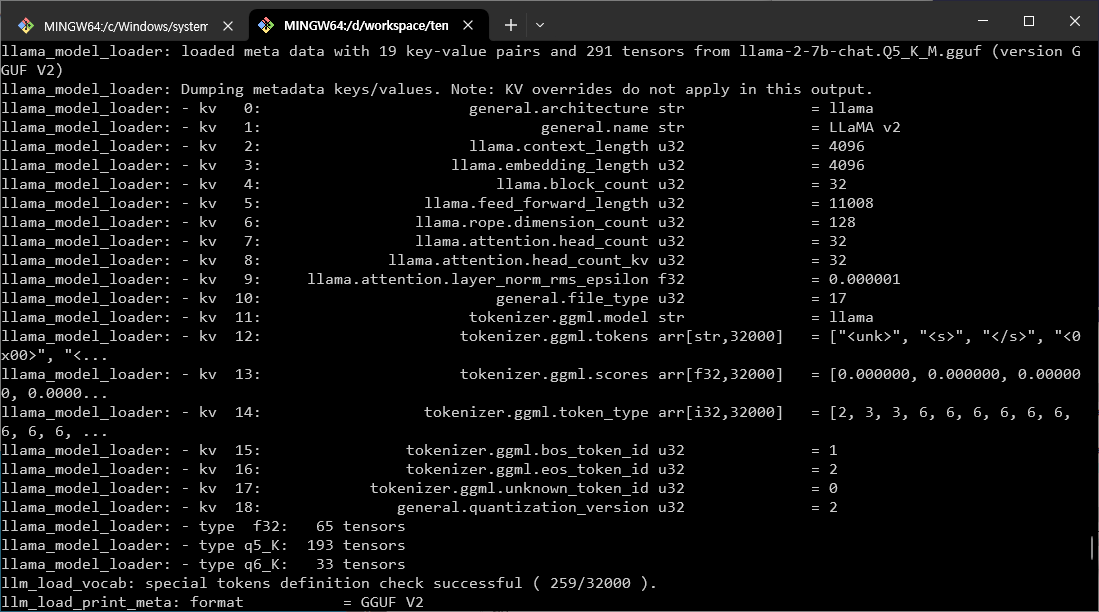

'개발' 카테고리의 다른 글
| Meta 의 오픈소스 llama3 모델 Windows 에서 실행하기 (2) | 2024.06.03 |
|---|---|
| Meta의 LLM 모델 LLaMA 2를 Windows에서 실행하기 (2) | 2024.06.03 |